


Similarité & Sémantique distributionnelle
La sémantique distributionnelle rassemble les mots par signafication et contextes. On appelle "similarité" la meusure de leur proximité sémantique.
La compréhension du concept de similarité en sémantique distributionnelle est donc une clé de succès dans la prise en main du framework. Or comme nous allons le découvrir, cette notion N'EST PAS celle admise par la langue française:
Se dit de choses qui peuvent, d’une certaine façon, être assimilées les unes aux autres (Larousse)
En sémantique distributionnelle la similarité se rapproche davantage de la notion d’alternative, ce qui en fait notion plus large que dans la langue française courante. Par exemple dans l’expression “ingénieur en conception mécanique”, le mot “mécanique” peut accepter le mot “électronique” comme alternative dans le sens où ces deux formulations sont tout autant probables a priori. Pour autant, dans le cadre d'un recrutement, les mots “électronique” et “mécanique” ne sont pas similaires dans la sens français où ils seraient assimilables. En effet recruter un ingénieur en mécanique en lieu et place d'un ingénieur en électronique peut conduire à de facheux problèmes... Mais comme nous le verrons ensuite, la sémantique distributionnelle nous permettra bien sûr de correctement les distinguer.
Pour appréhender la notion de similarité en sémantique distributionnelle, nous prendrons une approche géométrique: imaginons une boussole dont l’aiguille s’oriente selon le contexte d’une discussion : si on parle de “conception mécanique” elle s’arrête dans la zone “mécanique”. Elle agirait en quelque sorte comme un “détecteur de discipline”.
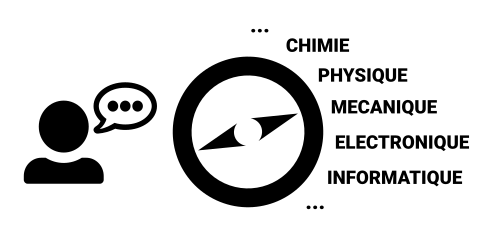
Cette boussole nous permet de détecter une discipline mais nous souhaitons aussi spécialiser notre discours sur le secteur Automobile et gérer cette information supplémentaire : comment faire ? Pour intégrer cette information, on ajoute à notre boussole un second axe qui lui permet de s’orienter dans les 3 dimensions de l’espace : elle est maintenant capable de détecter une discipline appliquée à un secteur d’activité.
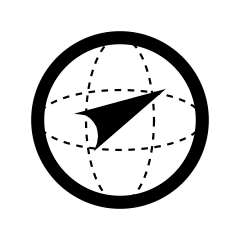
Maintenant si nous souhaitons prendre en charge d’autres informations, comme les logiciels de Conception Assistée par Ordinateur ou les normes, il nous faut une boussole qui s’oriente dans plus de 3 dimensions. Selon les sujets traités, les ensembles sémantiques que nous utiliserons ont de 100 à 300 dimensions. Ces niveaux de dimensions nous permettent de distribuer les mots dans l’espace avec suffisamment de liberté pour qu’ils y soient répartis par cooccurrence (selon leurs voisinages courants) et ainsi les rassembler par contextes, par sujets. C’est la sémantique distributionnelle. Par cette méthode et pour un profil détaillé, nous orientons notre « hyper boussole » de façon suffisamment précise, sans avoir recours à l’usage de catégories.
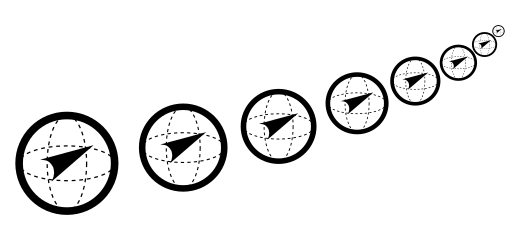
On peut alors entrevoir grâce à ces dimensions multiples, que la confusion initiale entre “ingénieur en conception mécanique” et “ingénieur en conception électronique” peut être résolue par élargissement du contexte d’étude des alternatives: dans l’expression “ingénieur en conception mécanique sous ProEngineer” alors le mot “électronique” n’est plus une alternative probable à côté de ProEngineer qui est une logiciel de conception mécanique. C’est l’empilement des détails dans le contexte qui font migrer la similarité de son sens global d’alternative vers la similarité telle que définie en français. Car après tout, pour une personne qui serait totalement naïve des disciplines que sont la mécanique et l’électronique; ne peut on pas dire que ces deux mots seraient bien des alternatives équivalentes ?
En cas des difficulté à évaluer une similarité entre deux mots, vous pourrez utiliser le concept d’alternative: remplacer un mot dans une phrase fait il d'elle une phrase plus probable ou moins probable ? Et ceci en respectant le contexte global, c'est à dire le reste du document ? Cette approche permet d'envisager un autre concept, celui de corpus ou de dictionnaire dans le framework. Deux mots ont un score de similarité entre eux qui est relatif à un corpus d'apprentissage. L'intelligence artificielle apprend à l'aide d'un corpus à évaluer des probabilités de voisinage, de co-occurence, dans un ensemble de phrases.
Prenons la description d'un métier, c'est un document. Prenons un ensemble de descriptions de métiers à partir d'un référentiel en ressources humaines et mettons les bout à bout: nous avons construit un corpus. Si nous entrainons un modèle de distribution sémantique sur ce corpus nous pourrons alors évaluer des similarités entre deux mots ou deux phrases. Pour rappel, ces similarités seront relatives au corpus d'apprentissage.
Pour l'évaluation de similarité entre deux documents, comme une expérience professionnelle et une opportunité par exemple, nous élargissons le concept d'alternative aux phrases complètes.
Pour comparer deux phrases il nous faut répondre à la question: dans le cadre limité du corpus d'apprentissage, est ce que ces deux phrases sont substituables ?
Exemple de comparaisons d'expressions professionnelles
Voici dans le tableau suivant une listes d'exemples de phrases comparées par le modèle disponible fourni avec le framework. Cet exemple montre la puissance de l'analyse sémantique car les expressions sont composées de mots différents mais finalement sont correctement rapprochées.
| Phrase 1 | Phrase 2 | Similarité |
|---|---|---|
| Serveur dans un bar à cocktails | Barman dans un café restaurant | 83% |
| Serveur dans un bar à cocktails | Administration du serveur web | 37% |
| Développement de sites web sous framework Symfony | Conception PHP sous Laravel avec JavaScript et html | 77% |
| Gestion des paies et notes de frais, établissement des fiches de paies, déclarations URSSAF | Gestion comptable des salaires | 75% |
| Développement de sites web sous framework Symfony | Conception PHP sous Laravel avec JavaScript et html | 77% |
Exploration en 300 dimensions & Visualisation des similarités
Explorer le lexique et les usages des mots dans le Répertoire Opérationnel des Métiers et des Emplois (ROME) dans un espace vectoriel en 300 dimensions sur le Projector de TensorBoard

L'avantage d'utiliser Projector de Tensorboard est qu'il tient compte de la valeur de similarité dans l'espace d'origine, même dans sa visualisation en 3D: en sélectionnant un vecteur, donc un mot, Projector recherche les mots les plus similaires dans l'espace natif de 300 dimensions et les met en avant dans le visuel en 3D. On peut ainsi s'apercevoir que les similarités en 300 dimensions sont altérées pour "rentrer" dans les trois dimensions du visuel: les points les plus similaires ne sont pas tous les plus visuellement les plus proches.




{kind=link}
{kind=link}