

La sémantique distributionnelle est une approche statistique du sens des mots où l'on suppose que les mots qui apparaissent dans des contextes similaires ont des significations apparentées (hypothèse de Harris). Attention justement à l'usage des mots : on parle bien ici de significations apparentées et non pas d'équivalence ni d'égalité de signification. La notion de similarité que nous utiliserons tiendra compte de cette relation entre significations un peu complexe.
Les mots de sens proches ont tendance à apparaître dans des voisinages de mots similaires (wikipedia).
La méthode de vectorisation de mots, est aussi appelée : word embedding, plongement de mots et plongement lexical. Elle consiste à réaliser une sémantique distributionnelle en utilisant des vecteurs dans un espace vectoriel. Les mots sont alors remplacés et indexés par des vecteurs dont la répartition dans l'espace reflète la répartition des mots dans le texte. En conséquence, les mots co-occurents (présents simultanément) seront représentés par des vecteurs proches dans l'espace. C'est le nombre de dimensions de l'espace utilisé, souvent plusieurs centaines, qui permet de respecter la diversité des contextes d'un même mot.
C'est une intelligence artificielle sémantique non supervisée: le modèle mathématique n'est pas entraîné à reconnaitre ou à classifier mais à reflété un corpus de textes, dit corpus d'entraînement.
Dans l'espace vectoriel, les mot sont donc représentés par des vecteurs et leur proximité transcrit leur relation de parenté sémantique qu'on appelle similarité. La bonne compréhension du concept de similarité est une clé de réussite pour la prise en main de l'Assistance Sémantique au Recrutement.
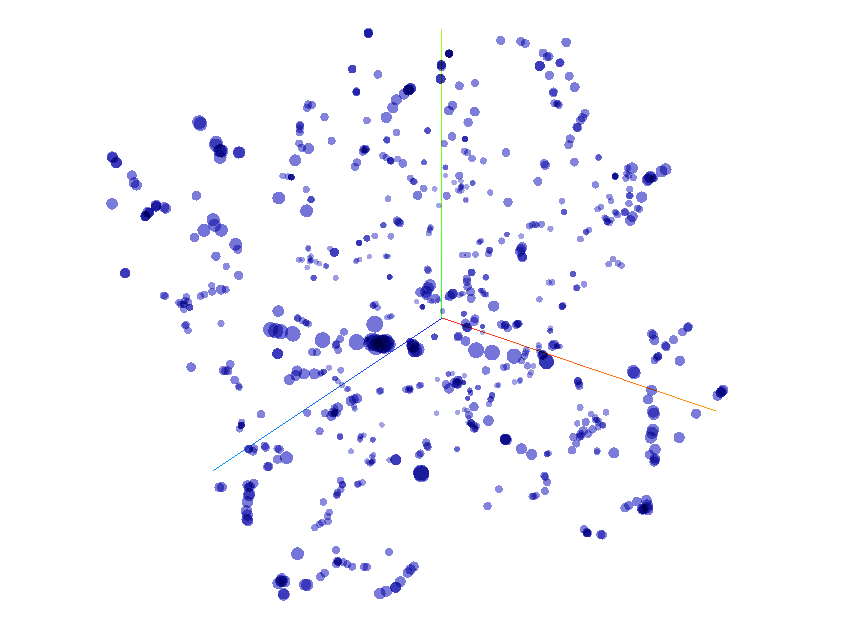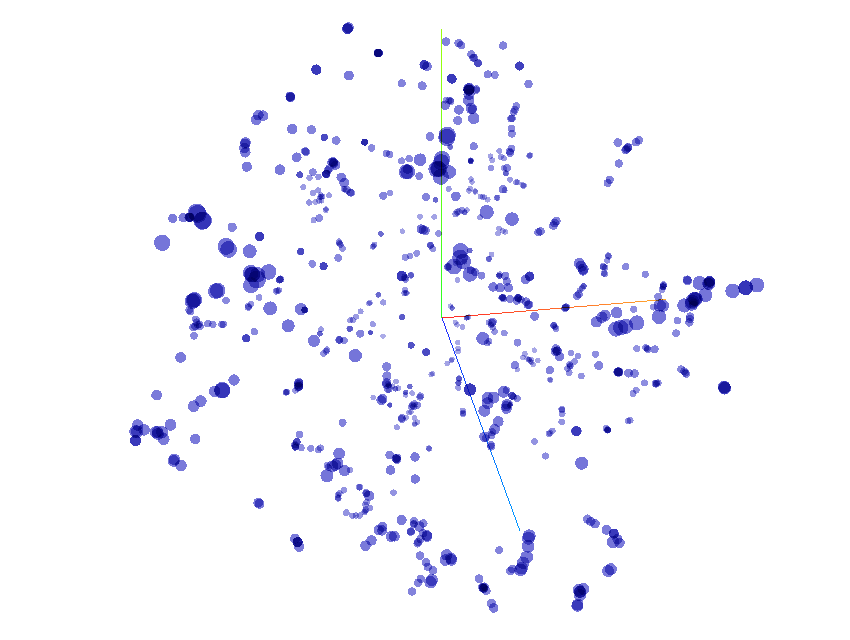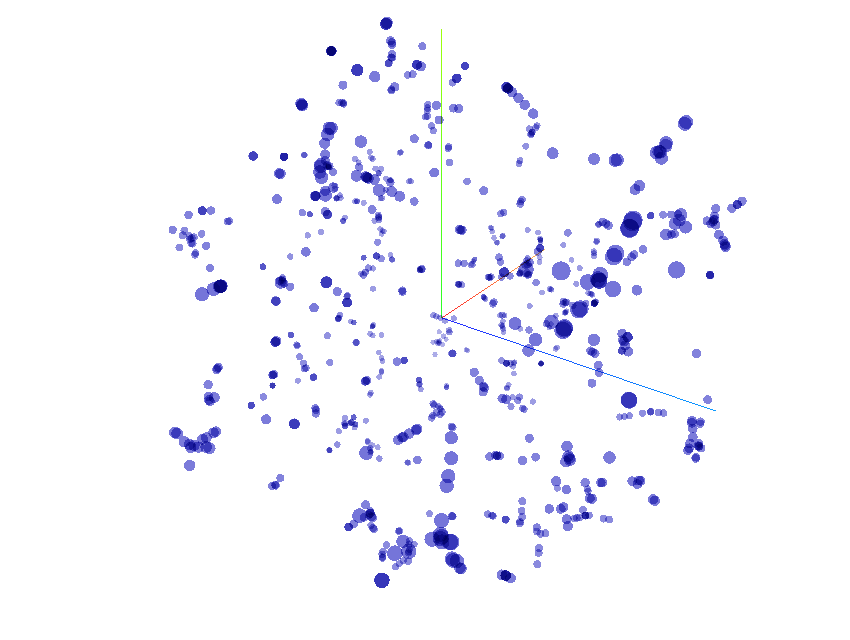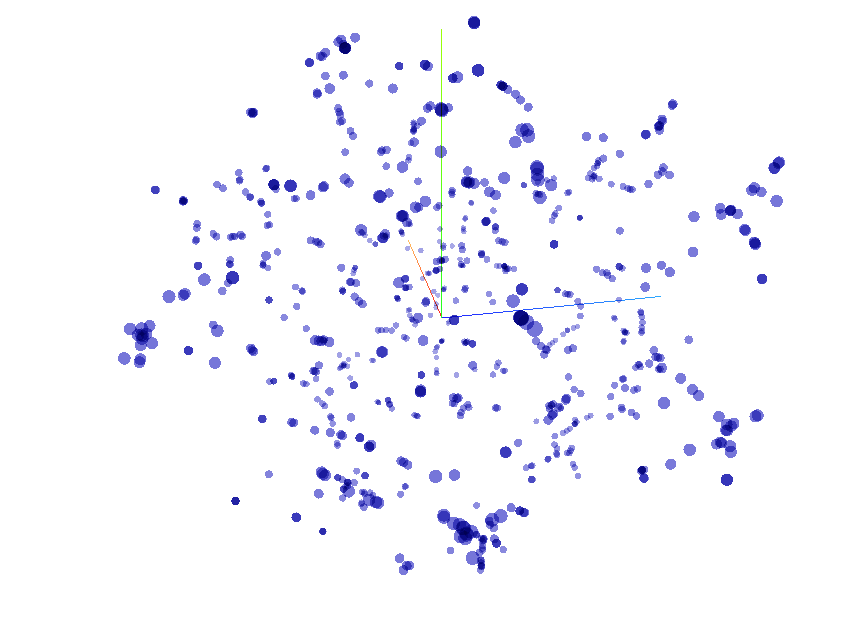
Distribution de 800 thèmes professionnels
Sur ce graphique interactif, vous pourrez explorer 800 points qui représentent 800 vecteurs thématiques distribués dans un espace en 3D.
C'est un espace vectoriel sémantique: il est partitionné en zones de significations apparentées. Localisez les groupes de points en pivotant le nuage de points sur ses deux axes pour remarquer les aggrégats sémantiques et les explorer.
Ce type de représentation est produite par la réduction dimensionnelle, opération mathématique qui vise à plier des espaces pour réduire leurs dimensions tout en respectant les relations géométriques de similarité. Ce graphique est le résultat d'une réduction de 300 à 3 dimensions. Cette division par cent des dimensions s'accompagne d'une simplification de la distribution; l'espace y perd beaucoup de sa complexité et donc de sa performance.
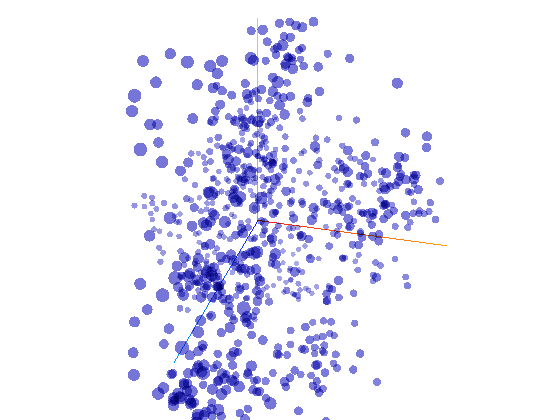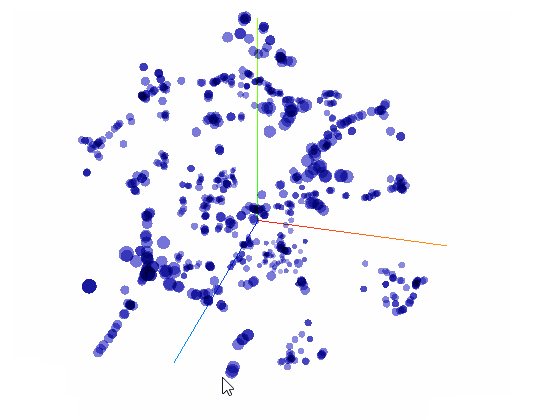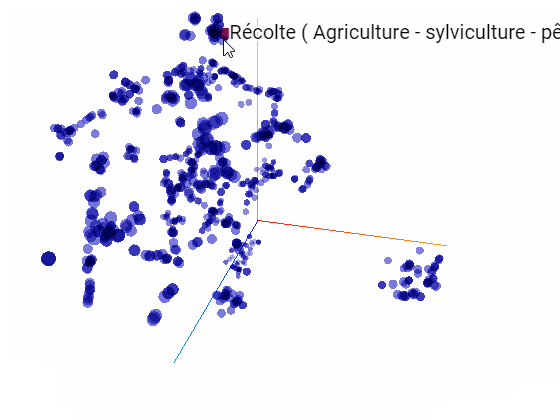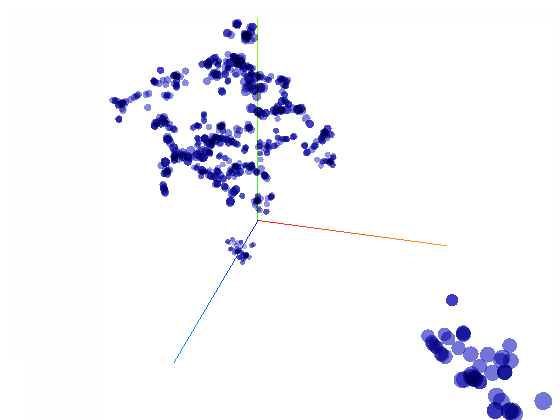
Il est possible d'explorer l'exemple précédent des 800 thèmes à la façon d'un espace vectoriel en 300 dimensions sur le Projector de TensorBoard

L'intérêt d'utiliser Projector de Tensorboard est qu'il tient compte de la valeur de similarité dans l'espace d'origine, même dans sa visualisation en 3D: en sélectionnant un vecteur, donc ici une expression, Projector recherche les expressions les plus similaires dans l'espace natif de 300 dimensions et les met en avant dans le visuel en 3D. On peut ainsi s'apercevoir que les similarités en 300 dimensions sont altérées pour "rentrer" dans les trois dimensions du visuel car les points les plus similaires ne sont pas tous visuellement les plus proches.
Voici une vue accélérée du processus: on peut y observer la construction d'aggrégats sémantiques en direct. Cette même transformation ("T-SNE") peut être réalisée sur d'autres dimensions d'espaces. Dans le graphique dynamique ci-dessous on peut explorer plus de 13 000 compétences du référentiel en ressources humaines ROME de pôle emploi. Cette représentation est une transformation de l'espace vectoriel de 300 dimensions à 2 dimensions.





{kind=link}
{kind=link}